Technical details
The vision element is written in C++ using the Open Computer Vision (OpenCV) libraries. (The OpenCV libraries are an open source project and is available from here if anyone wishes to play around with computer vision.)
The Connect 4 robots' vision is a multistage process with two main steps:
locating the board and determining the presence of pieces.
|
The uncorrected image from the webcam is distorted
due to the camera's wide field of view, see right.
To correct for this a collection of images of a
chess board were taken with the same web camera
and are used to calculate the optical
distortion. This allows images to be corrected
such that straight lines appear more-or-less
straight. |

uncorrected image, click to enlarge
|
|
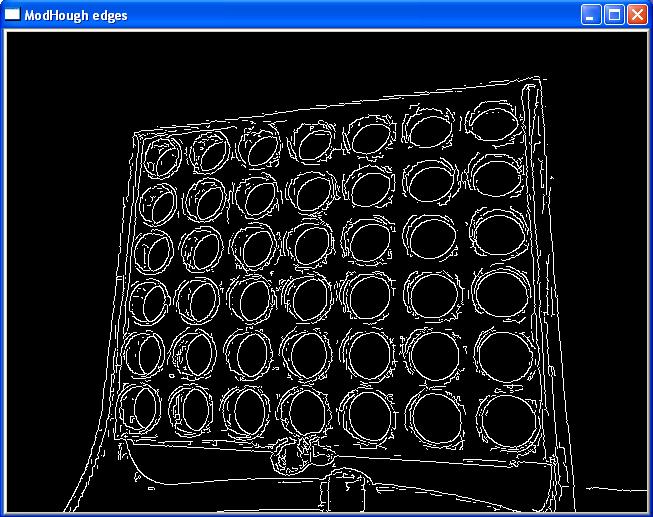
Having corrected any optical distortion the "edges" of
objects are found using a Sobel filter. A
Sobel filter identifies the places in the
image that have the sharpest change in
intensity. |
edges image, click to enlarge
|
|
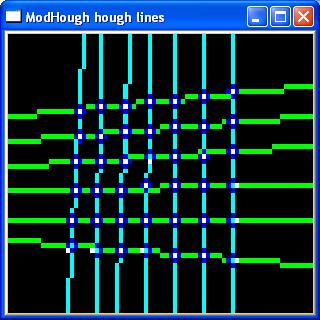
Next a Hough transform is applied to the "edges image" to
calculate the probability of the centre of a
circle appearing at each point in the image. This
produces fuzzy blobs around where the centres of
circles are most likely to appear. |
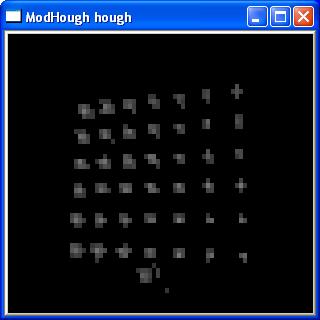
hough transform, click to enlarge
|
|
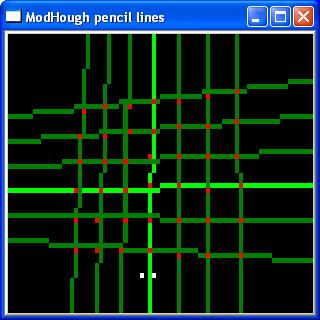
A threshold is applied to the fuzzy "circle centre" blobs
(removing points with low probability) and
then a clustering algorithm is used to
determine the centre of each blob. This
results in an image with each point
representing the most likely place that a
centre of a circle might lie. |
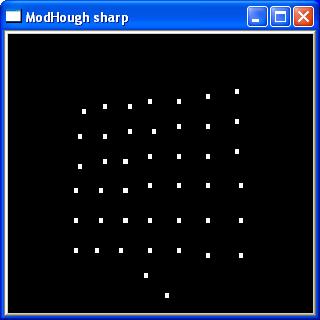
likely centres, click to enlarge
|
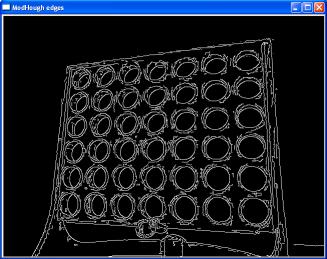
An iterative process now starts, which attempts to fit horizontal and vertical lines through the points. (A horizontal line being defined as a line
that lies within +/- 10 degrees of horizontal in the image and a vertical line is one that lies within +/-5 of vertical within the image).
The process goes as follows:
(i) A first attempt is made to fit horizontal and vertical lines.
(ii) Any point that doesn't lie very close to a line is assumed to be erroneous and is removed.
(iii) The lines are removed and refitted to the remaining points.
Repeat (ii) and (iii) until no more points can be deleted, or all the points are deleted (in which case it was a bad image).
The result is shown below:
The horizontal and vertical lines found in the step above are projected until they meet each other. The two places where the majority of the lines
meet is taken as being the horizontal and vertical vanishing point
for the image (see artistic literature on perspective in drawings). Using these two
vanishing points as a guide the system then finds the best fit of a 6 by 7 grid (i.e. something matching the shape of a connect 4 board) to the likely circle centres from step 4 above.
These last two steps may seem complex but by knowing it is looking for a regular board, consisting of an array of circles, and then estimating its likely vanishing points, the system can robustly adapt (within
reason) to different positions and poses of the connect 4 board within the image seen by the camera.
Having estimated the location of the board the system checks for the presence of pieces at each of the estimated circle centres of the board. It samples the colour around each circle centre and then determines whether a piece is there or not using a set of rules which were learnt using a decision tree trained on previous images of connect 4 boards. The rules roughly correspond to checking how blue the region is but also take into account varying lighting conditions.
The result, shown below, indicates the location of pieces with green 'x's and blue 'e's for empty locations.
The system is colourblind for red and yellow pieces - it only checks if a piece is there or not. Varying lighting conditions can make distinguishing
between red and yellow very hard, i.e. a bright spot of reflection off a red piece can make it look yellow, whereas deep shadow on a yellow piece can make
it look red. To get round this we (as humans) typically move our heads.The system can't control the placement of the camera so it has to live with
reflections and shadows. Thus it is much more reliable if it ignores red and yellow and uses the order of play to
determine colour. NB this also means the system can't detect if someone plays the wrong colour.
A few checks are performed on the machine's interpretation of the image;
(i) it ignores any images where it can't identify all 42 circle centres of the board - this helps it avoid seeing peoples hands as pieces when they wave them in front of the board; many people's skin colour is very similar to the red-yellow colour it looks for in order to identify pieces,
(ii) when waiting for someone to play, it double checks any new piece that it thinks it has seen by using two images obtained at least half a second apart -- the arm will start moving in this time but will abandon its play if the double-check fails,
(iii) because pieces can't float in thin air it will only check for new pieces in the empty space above pieces that it is convinced that it has previously seen played.
|