Project Title
|
Bayesian Multisensory Scene Understanding
|
|
Abstract |
|
We investigate a solution to the problem of multi-sensor perception and
tracking by formulating it in the framework of Bayesian model selection.
Humans robustly associate multi-sensory data as appropriate, but previous
theoretical work has focused largely on purely integrative cases, leaving
segregation unaccounted for and unexploited by machine perception systems.
We illustrate a unifying, Bayesian solution to multisensor perception and
tracking which accounts for both integration and segregation by explicit
probabilistic reasoning about data association in a temporal context.
Explicit inference of multisensory data association may also be of intrinsic
interest for higher level understanding of multisensory data.
We illustrate this using a probabilistic model of audio-visual data in
which unsupervised learning and inference provide automatic audio-visual
detection and tracking of two human subjects, speech segmentation, and
association of each conversational segment with the speaking person.
|
|
Related Publications
|
- Timothy Hospedales, Joel Cartwright and Sethu Vijayakumar,
Structure Inference for Bayesian Multisensory Perception and Tracking,
International Joint Conference on Artificial Intelligence (IJCAI '07).
[pdf]
- Timothy Hospedales and Sethu Vijayakumar,
Structure Inference for Bayesian Multisensory Scene Understanding,
Submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence
|
|
Schematic |
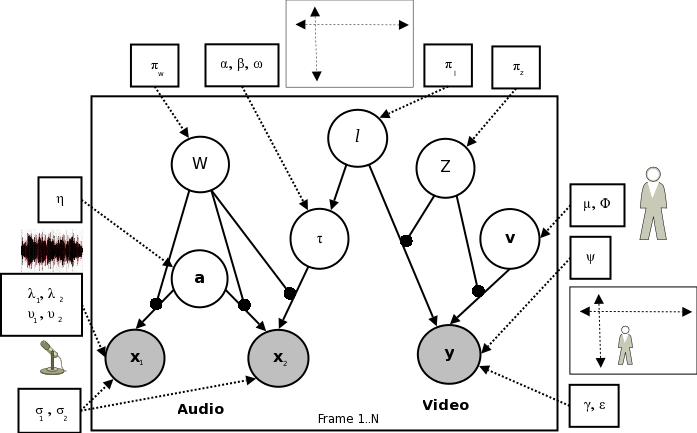
Graphical model used for inference
|

Results: Speaker Association and Tracking
|
| Sample Data and Results |
|
Description: Video files are divx codec with stereo sound. Based on the stereo TDOA and video data we can learn to track the source audio-visually. Depending on the experiment, some datasets may use separate train/test data and some sets may use just one sequence.
Multiuser: Test data sequence and manually labelled ground truth are provided.
Ground truth files are matlab format with
three fields which should have the same number of entries as frames in
the video file. These are: l[1,2]: horizontal axis location of user 1
& 2 {1-120 pixels}, z[1,2]: visibility of user 1 & 2 {0: invisible, 1:
visible, 2: partially visible}, w[1,2]: audibility of user 1 & 2 {0:
user silent, 1: user audible}. Results: Annotated video is fairly self
explanatory. The 'fixed stereo' version uses user inference to put the
speech of user 1 & 2 on channel 1&2 respectively. The 'moving stereo'
version uses user inference & user position inference to put the
speech of the user on the appropriate channel depending on where they
are. (Try listening to both of these with headphones!)
Mechanical: Easiest sample has maximum volume, spectrum width, lighting.
Hardest sample has minimum volume, spectrum width and lighting.
|
|
|
|